
Lecture13 Attention
UMich EECS 498-007 Deep learning-Attention
前言#
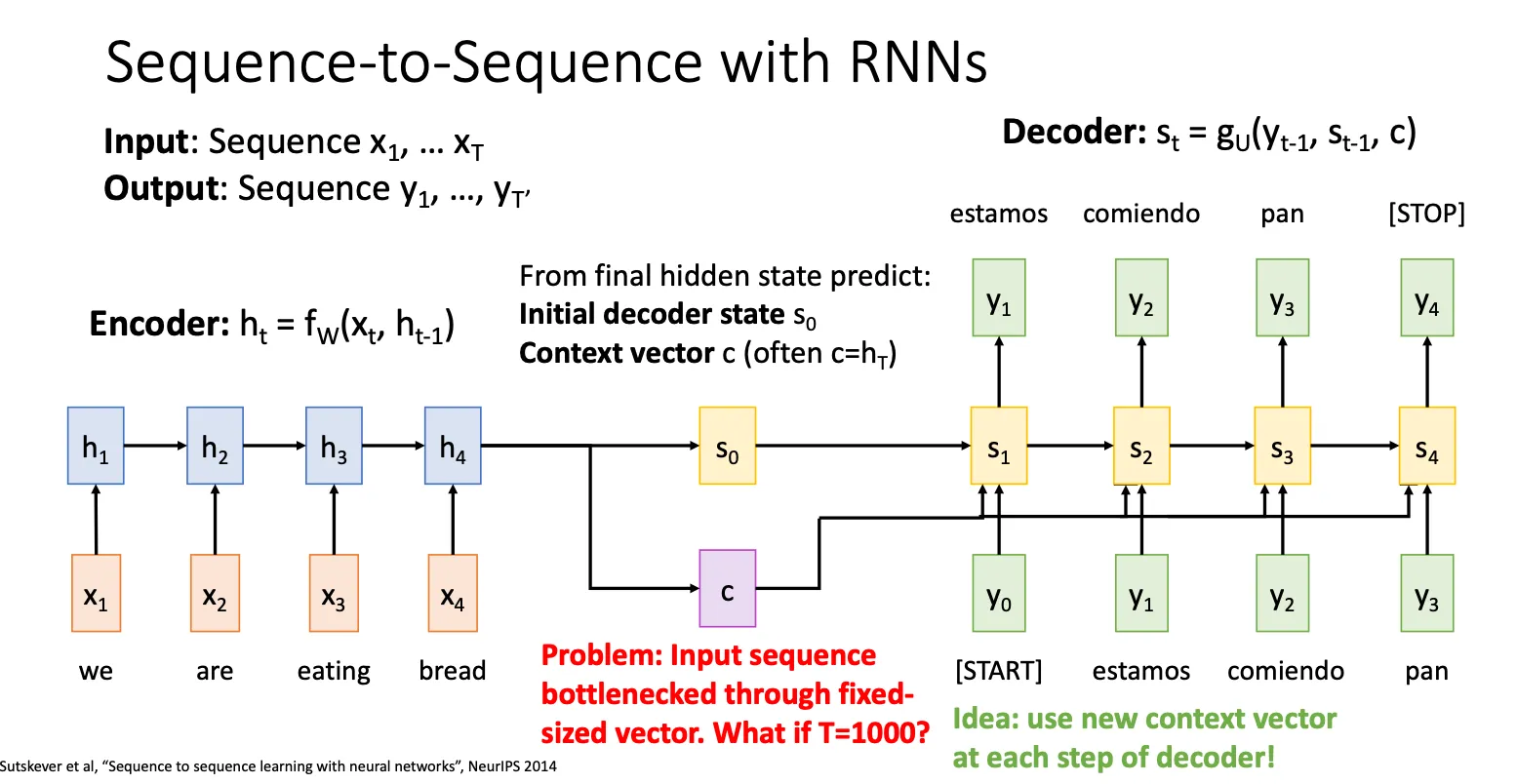
之前提到的RNN架构看起来挺好的,注意这里的图和Lecture 12的图是有一些差别的,他多了一个c向量,这里的 c 和 都是 。然后这里每次c还被连接到解码器的每一个时间步,与上一步的输出(y₀, y₁, y₂…)一起作为当前时间步的输入。因为如果 c 只用来初始化解码器,那么在生成很长的输出序列时,解码器可能会逐渐“忘记”最开始的上下文信息(因为RNN的隐藏状态在不断更新)。通过在每一步都将 c 作为输入,模型被不断地提醒原始句子的全局信息是什么。这极大地帮助模型保持翻译的一致性和准确性,防止信息丢失。
而Lecture 12就没有这个 c,这里是一个小变化。
但是即使这个架构看上去挺好的,但是如果你的上下文很长,你的所有信息都被压缩进这一个向量里面,这就有点不make sense。
Attention#
终于来到大名鼎鼎的注意力了,他的思想就是当处理decoder的状态 的时候,他会遍历encoder中的每一个状态 ,然后通过一个MLP 函数计算出他们的alignment scores,通过softmax归一化之后得到attention score。直观上理解就是得到当前模型觉得当前状态和之前的哪一个状态关系最密切,这样的一个分数。然后每一个attention score和对应的状态相乘再相加得到下一个状态的context vector,最终得到下一个状态,以此类推。
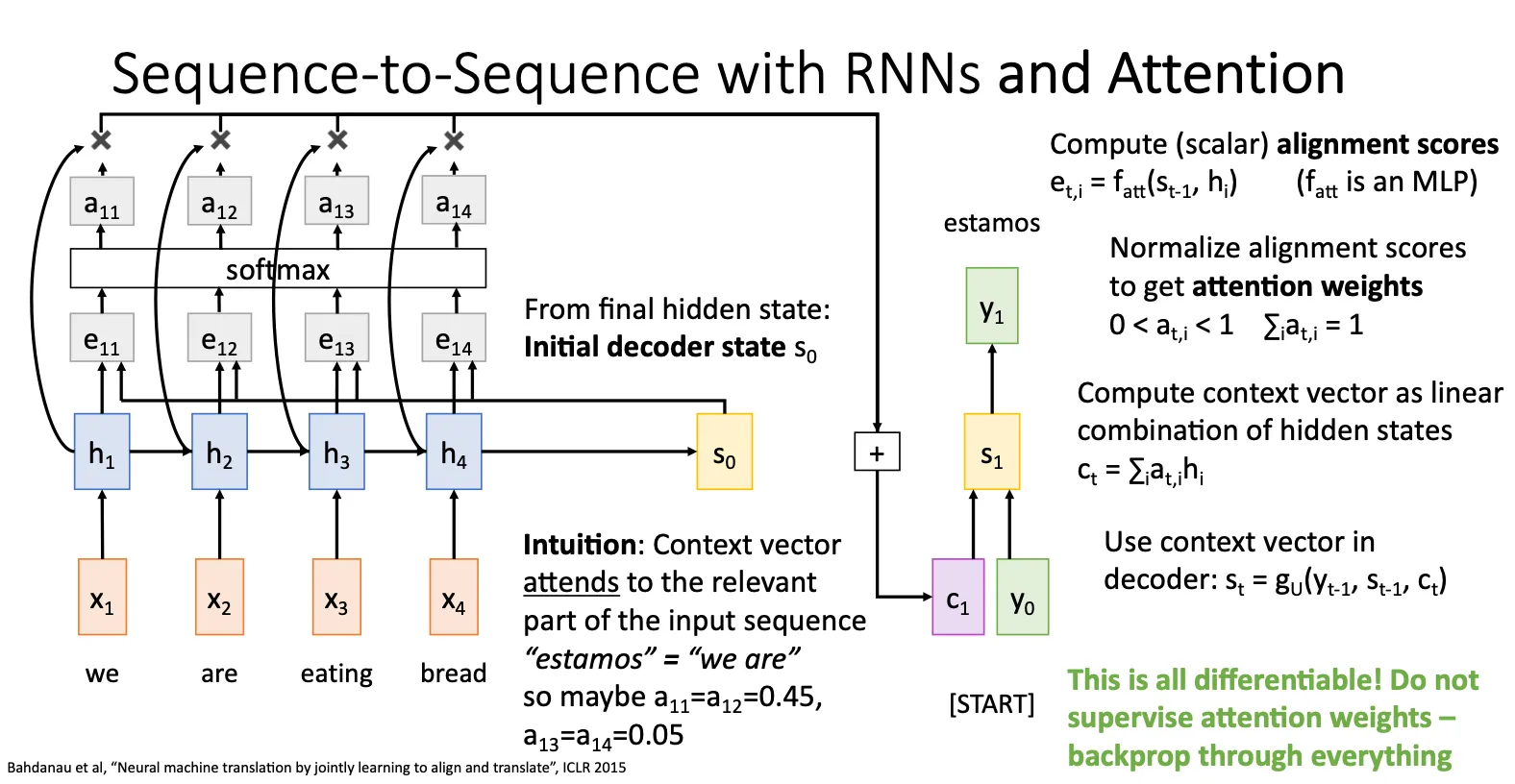
优势就是他解决了之前提到的bottlenecked的问题,而且上述的所有操作都是可导的,意思就是不是我们高速模型应该注意什么,而是模型自己决定自己要注意什么。
有意思的是,在上述过程中,attention机制并没有用到 是一个连续的这样一个特征,只是像从一个集合中提取出一些 ,但并这不意味着attention没有用到连续这样一个特征,因为这个特征已经被包含在 本身中。所以attention更本质的就是可以自由地、非线性地从{h₁, h₂, h₃, h₄}这个信息池中直接提取,而不需要像RNN那样必须按h₁→h₂→h₃→h₄的顺序回溯。
既然解码器只关心一个“向量集合”,那么这个集合不一定非要来自RNN编码器。它可以来自任何能将输入(如图片、声音等)转换成一组特征向量的模块。这极大地扩展了注意力机制的应用范围,使其成为一个非常灵活和强大的工具。
Image Captioning#
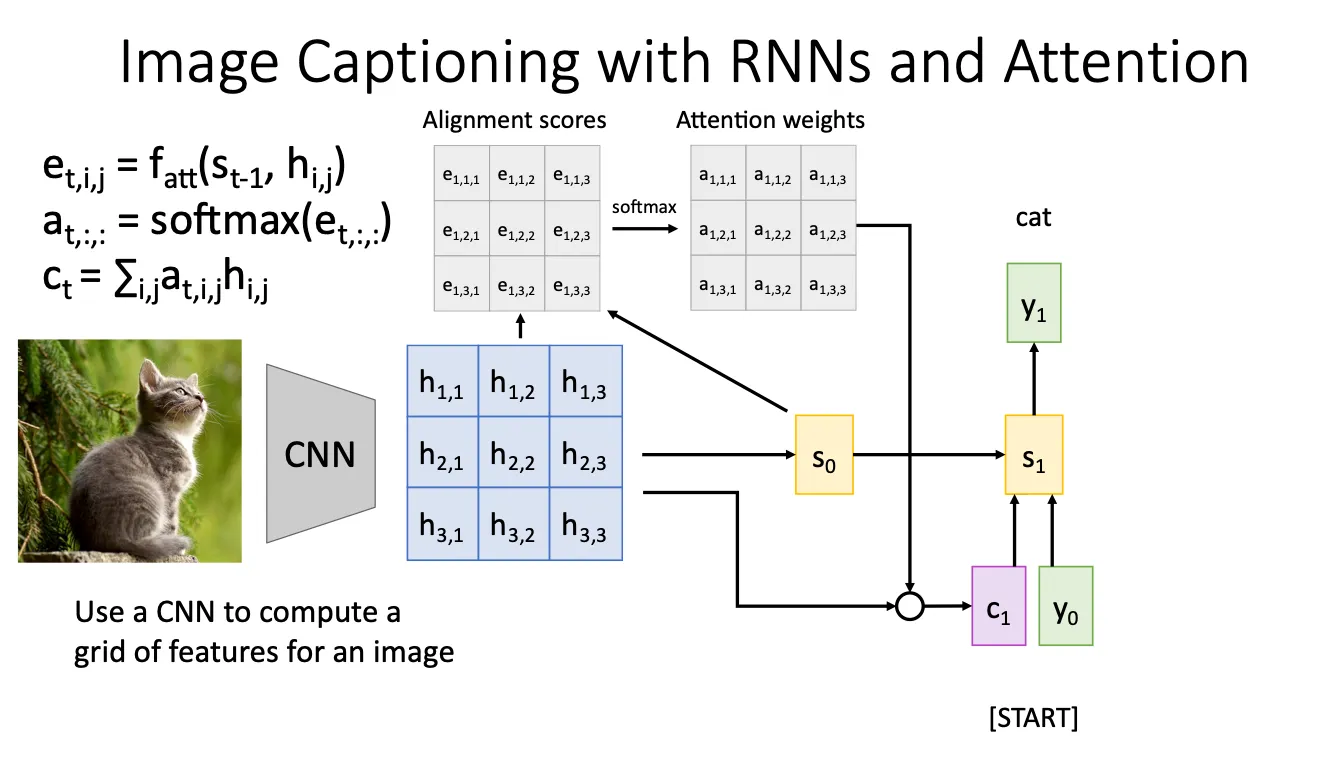
上面说到,attention这种机制拓展了他的应用范围,于是我们就将它用来图像字幕生成,基本思想都是一样的,只不过我们将图片经过CNN之后会得到一个a grid of features for an image,然后就把每一块当作 然后之后就类似,计算alignment score和attention score,然后重复。
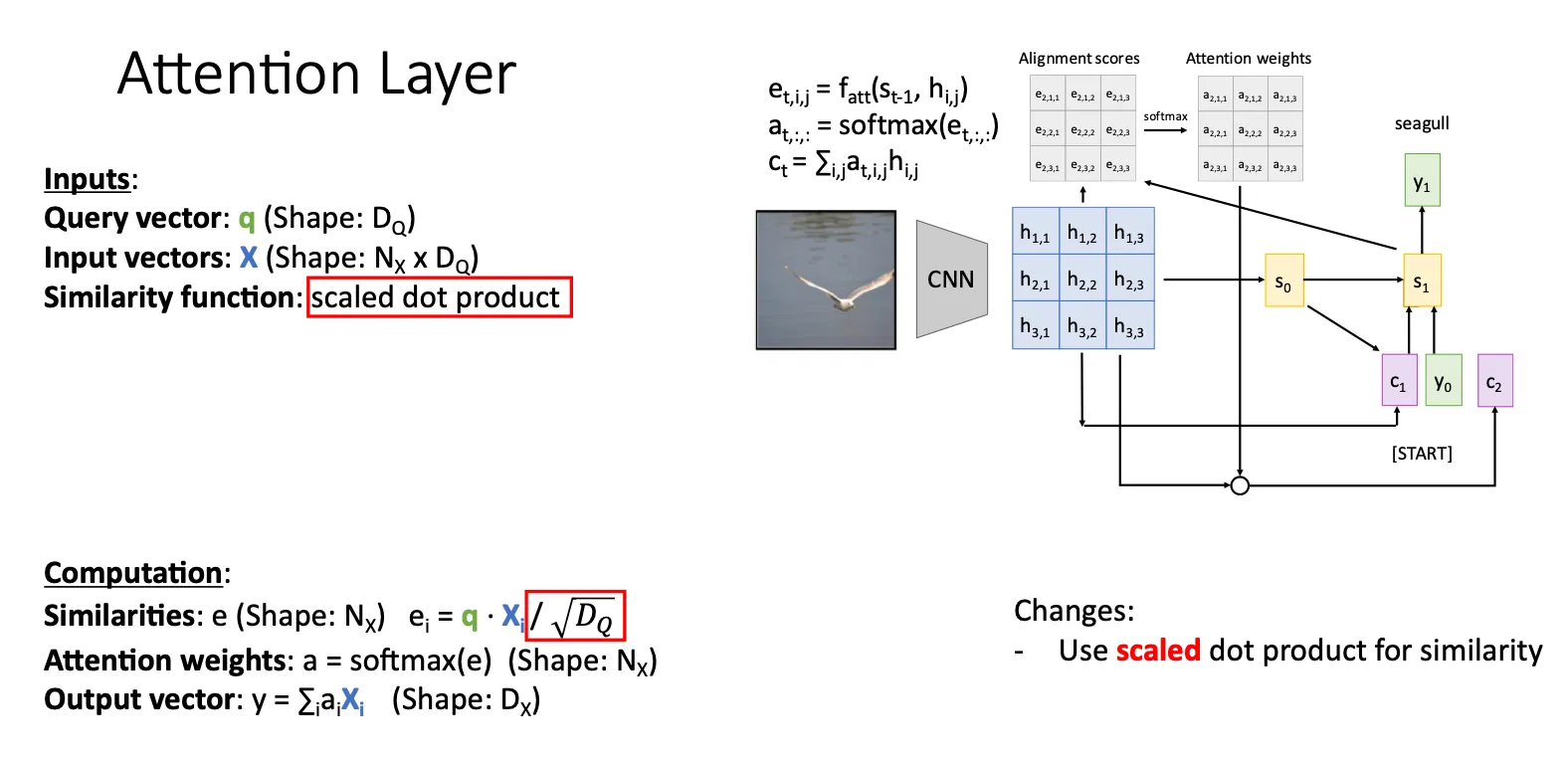
Attention Layer#
这里我们定义一些东西ppt中的query vector就是q就是,然后input vector就是之前的状态。 随后我们对之前的架构进一步改进,我们将 改成scaled dot product,trail and error发现点乘已经足够好的描述两个向量之间的相似度而且还简单。那什么是scaled呢,就是我们将两个向量点乘之后再除一个 目的就是为了避免当维度 较大时, 和 的点积可能会变得非常大,导致:
- 经过 softmax 之后的分布非常“尖锐”;
- 梯度会很小,容易引发梯度消失或训练不稳定;
- 模型容易陷入局部最优。
例如,如果 中的数值是几十甚至上百,softmax 之后就会非常偏向于某一个 token,其他信息会被忽略。
 那么这时有一个问题,为什么不两个向量归一化后进行点乘,这样得出来的就是余弦相似。答案就是(来自chatgpt)
那么这时有一个问题,为什么不两个向量归一化后进行点乘,这样得出来的就是余弦相似。答案就是(来自chatgpt)
-
训练效率和表达能力更强 Dot product 是线性可微、连续可导、更适合训练。 余弦相似度中 和 是平方根操作,会造成非线性传播更复杂。 不对向量归一化,能让模型通过学习 自由地调节“相似度尺度”。 不归一化 = 模型可以同时学习“方向 + 强度”,表达能力更强
-
效率问题 点积可以通过矩阵乘法高效并行计算(在 GPU 上非常优化) 标准化(归一化)向量涉及除法和开根号,不好并行也会更慢 softmax 本身已经是归一化过程,没必要再归一化一次
-
学习能力更强(有“幅度”信息) 余弦相似度只看“角度”,忽略了向量长度。 而 Transformer 中的注意力,允许模型根据向量长度(幅度)来表达置信度或重要性。 例如: 模型可以让一个词的 Key 更长来表达它“特别重要”,即使它的方向不一定最匹配。
-
softmax 本质上像是“可学习的归一化” Softmax 会自动把 dot product 缩放到 [0, 1] 的权重上 我们只需要它的相对值,不需要真的做 cosine
那问题又来了,既然scaled dot product这么好,为什么我们不所有的都使用这个呢,答案是(chatgpt) 就是有一些任务比如对比/分类中,我们希望忽略向量长度,只看方向
- “两个向量的语义是否类似” 是靠方向决定的
- 向量有多长(置信度高低、频率高低)反而是噪声
然后我们再改进一点,首先就是我们多了两个东西,一个是key,另一个是value。他的作用就是一个和X相乘得到K,用K来获得attention score;另一个就是用来和attention score相乘,就相当于将X拆分成两个部分,原本就是用相同的X来获得attention score以及和attention score相乘,现在变成用两个X的线形变化来分别执行。
为什么这样做呢?其一这两个矩阵是可学习的,那么其实就是相当于给神经网络更大的学习空间,更大的自由度;其二就是将它拆分就可以并行计算。
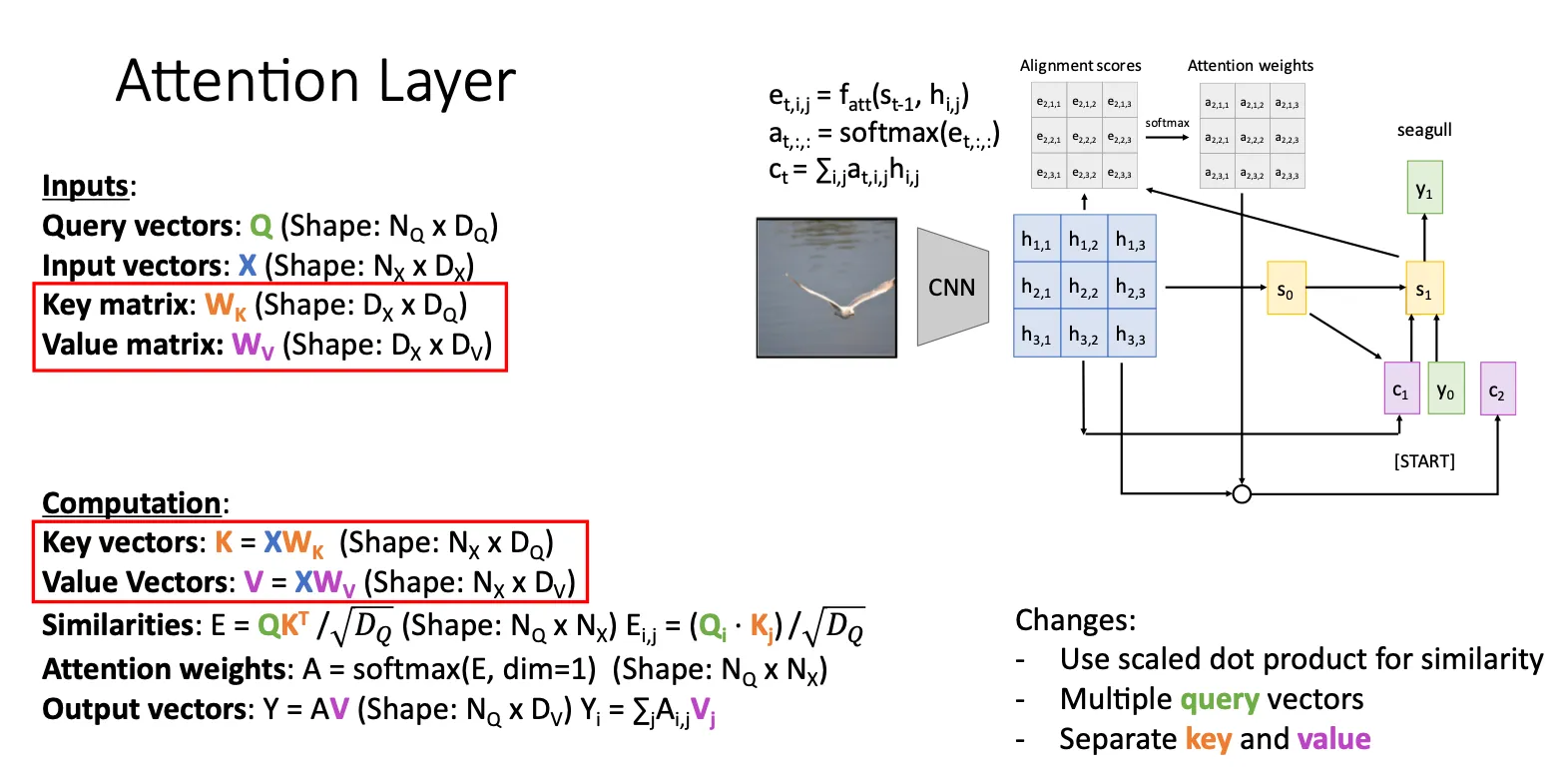 还有的改进就是他同时进行多个query的计算,也就是同时用多个计算。问题来了,我们难道不是用前一个 来推出下一个吗,那这怎么并行计算。
还有的改进就是他同时进行多个query的计算,也就是同时用多个计算。问题来了,我们难道不是用前一个 来推出下一个吗,那这怎么并行计算。
答案就是在训练的过程中我们采用的策略叫Teacher Forcing,我们实际上拿的是ground truth来作为输入,而不是上一次的输出作为下一次的输入。也就是说,所有的y都是ground truth,输出只是用来和groud truth比较然后计算损失函数,并没有作为下一次的输入。所以,这样子我们就可以并行的进行query计算。
下图描述的就是相应的流程
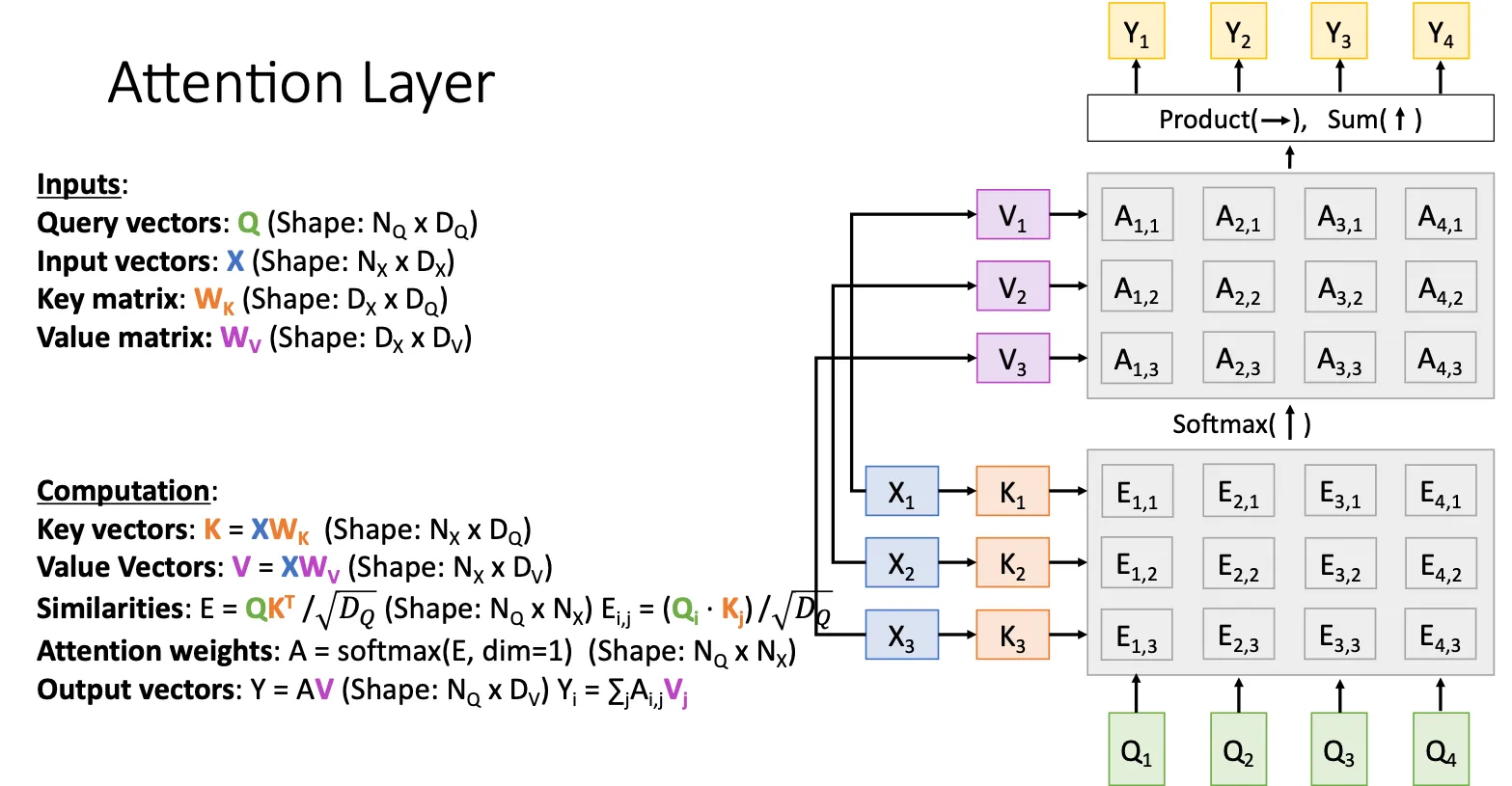 这里描述的其实不是一个特定任务的架构而是一个general的Layer,你有两组向量X,Q你就可以找一些场景然后将这个拼接进去。也很容易理解,就是我们想把某个特定的方法让他变得更general一点,所以我们的attention机制也就越来越抽象和泛化。
这里描述的其实不是一个特定任务的架构而是一个general的Layer,你有两组向量X,Q你就可以找一些场景然后将这个拼接进去。也很容易理解,就是我们想把某个特定的方法让他变得更general一点,所以我们的attention机制也就越来越抽象和泛化。
Self-Attention Layer#
这个属于特殊的情况,加入我们没有两组向量,我们只有一组X,那么思路就是我们再加一个矩阵用来生成query。然后他的架构就长下面这样
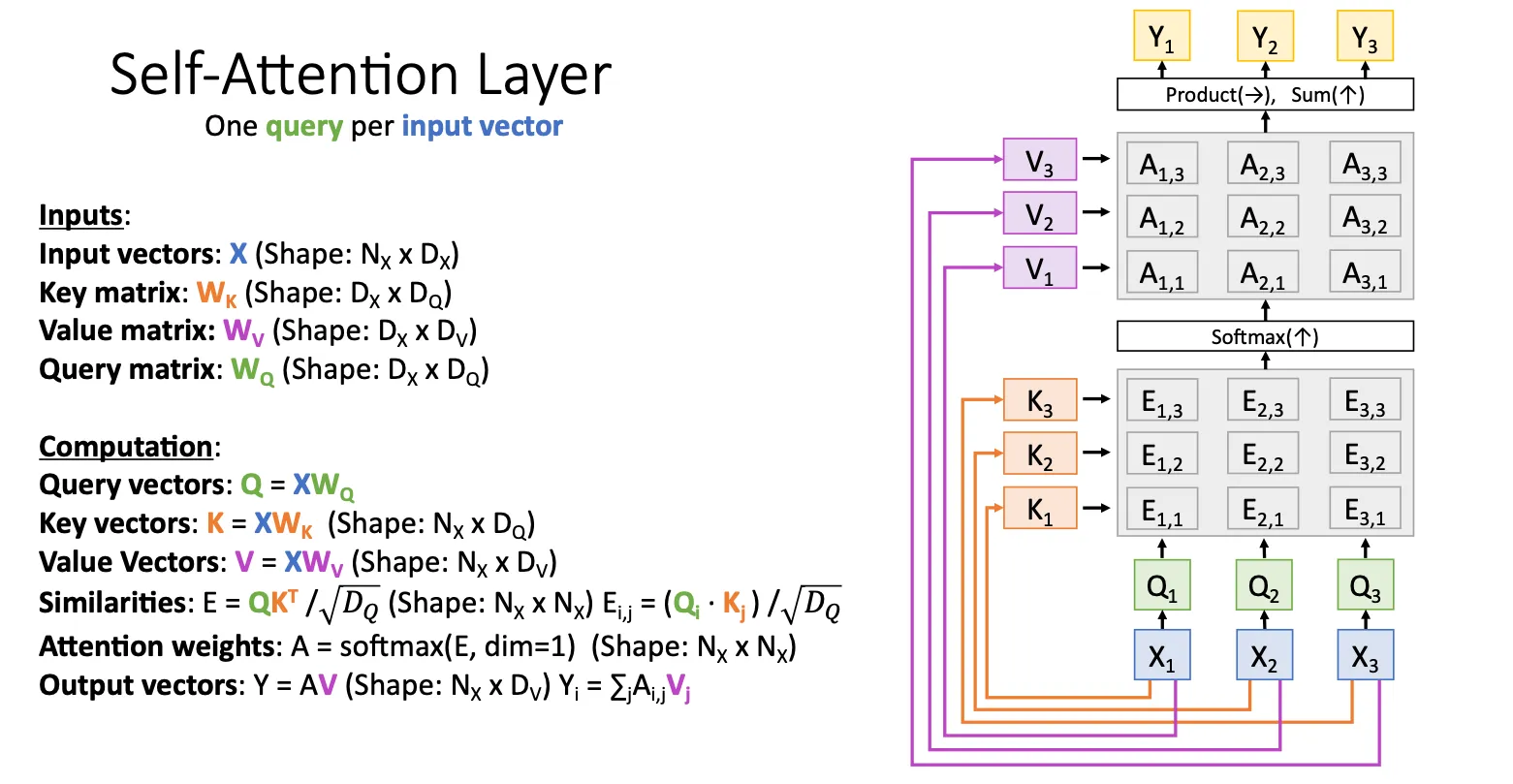 我们可以很容易就可以推出,如果我的输入输入顺序换一下,从 换到 那么我们的输出也会从原来的 对应的换成 ,也就是说,Self-attention layer是Permutation Equivariant(置换等变)。换句话说就是Attention不依赖输入顺序本身它只看 token 之间的相似性(通过 Query-Key 点积),而不在意 token 是第几位。这就让这个机制表达能力强,更通用,因为它可以处理各种顺序、不定长甚至无序的输入。Permutation Equivariance 说明 Attention 本身不偏向任何顺序结构——这是一种很强的结构对称性。
我们可以很容易就可以推出,如果我的输入输入顺序换一下,从 换到 那么我们的输出也会从原来的 对应的换成 ,也就是说,Self-attention layer是Permutation Equivariant(置换等变)。换句话说就是Attention不依赖输入顺序本身它只看 token 之间的相似性(通过 Query-Key 点积),而不在意 token 是第几位。这就让这个机制表达能力强,更通用,因为它可以处理各种顺序、不定长甚至无序的输入。Permutation Equivariance 说明 Attention 本身不偏向任何顺序结构——这是一种很强的结构对称性。
如果你在意顺序的话,你就必须显式地加入位置编码(positional encoding),否则模型无法理解顺序。

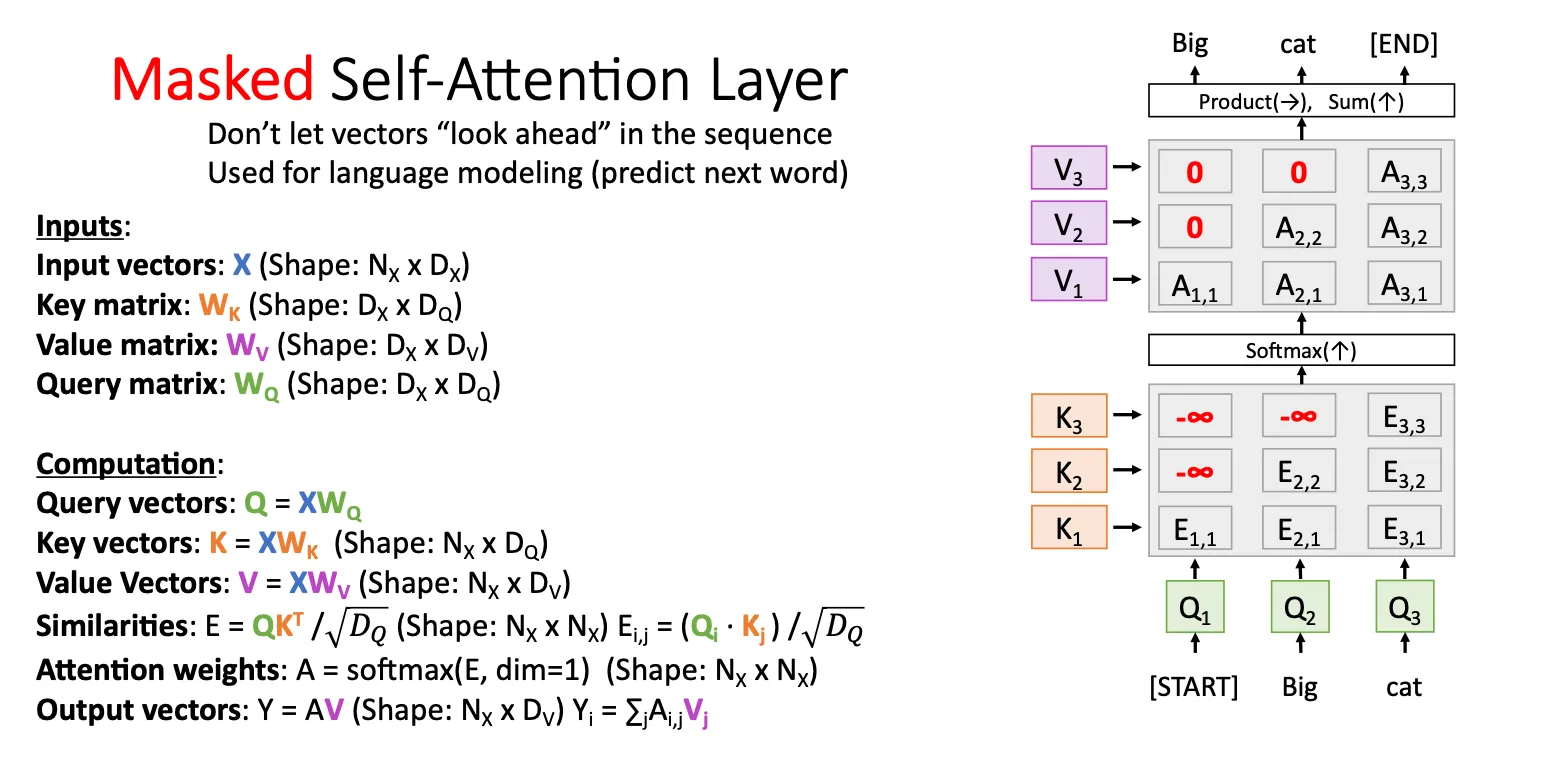
Masked Self-Attention Layer#
有时候,我们想让这个模型类似RNN一样,他不会提前知道下一个输入是什么,所以我们加一个mask,具体比如对于 他不会知道 是什么他只知道当前的输入,对于他不会知道,他只知道历史的输入
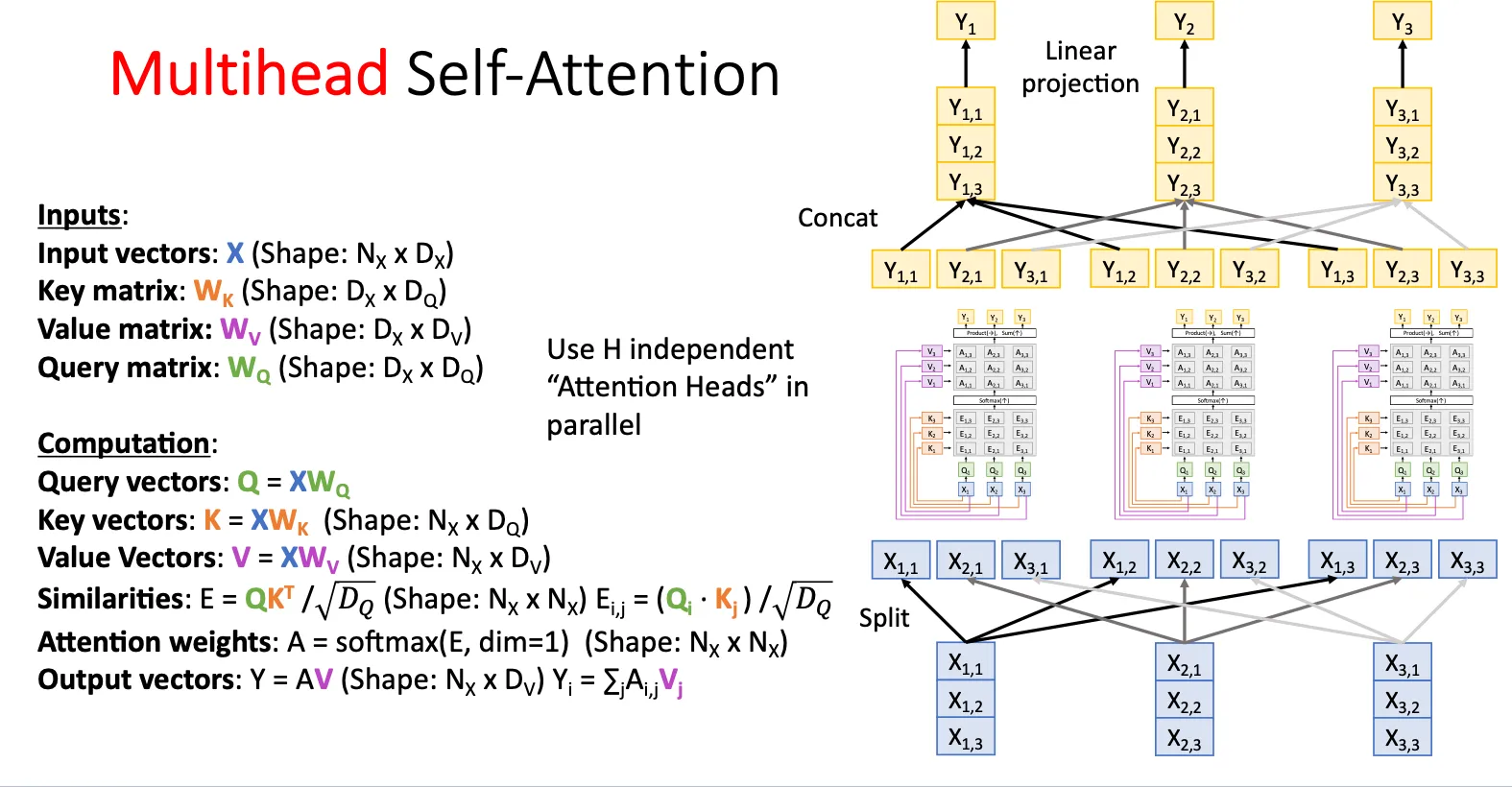
Multihead Self-Attention#
这个真的妙,多头注意力机制就是将一个query拆分,然后和别的query组合跑多个attention layer
每个头的, , 是不一样的,自己学习来的。直观上理解,他比单头学的更细。
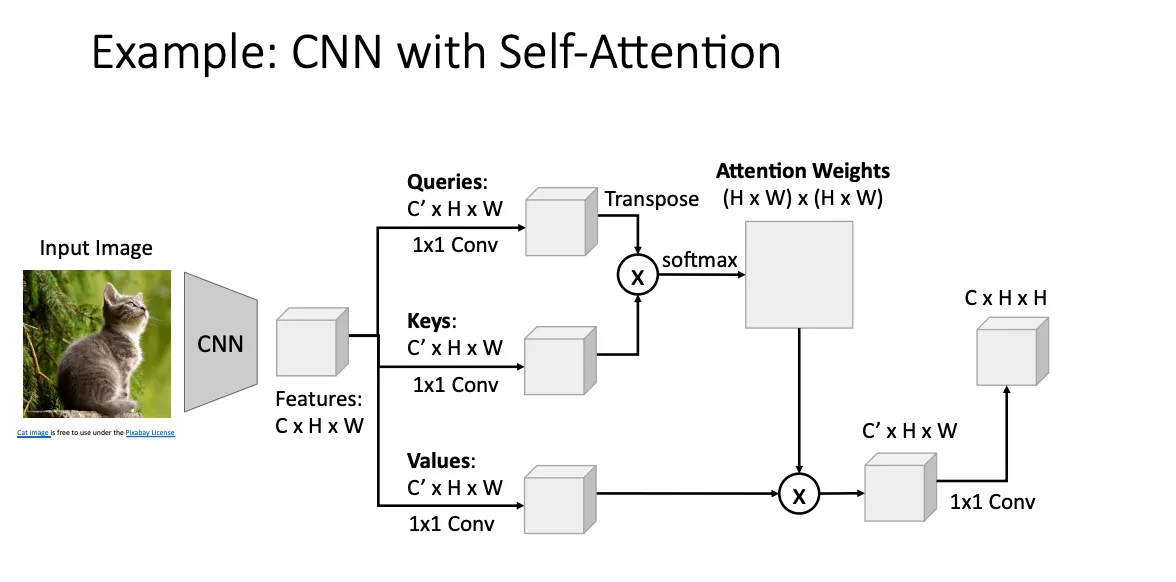
CNN with Self-Attention#
之前说self attention已经可以general成一个层了,所以这是把他用在CNN上的一个例子
Transformer#
这就是transformer layer的架构,将向量用多头注意力机制输入到Self-Attention layer中,然后经过Layer Normalization,MLP ,Layer Normalization,最终得到输出。中间还加了一些残差连接。
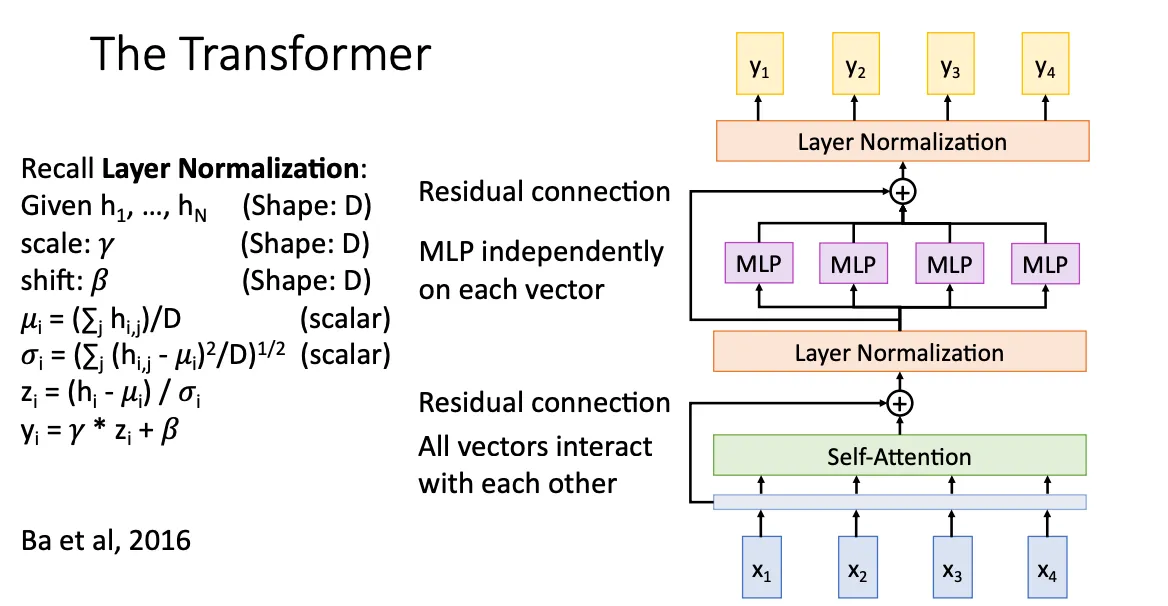 我们将transformer layer堆起来就组成transformer架构,这就是大名鼎鼎的Transformer。
我们将transformer layer堆起来就组成transformer架构,这就是大名鼎鼎的Transformer。
