自监督学习 CSMAE ISBI 2025 论文笔记
CSMAE - Cataract Surgical Masked Autoencoder (MAE) based Pre-training
前言#
这个文章的主要用的就是自监督学习里面的给图像加mask然后让模型预测mask的内容这种思路
主要方法就是MAE(VedioMAE)加一个token selection network,他的主要想法就是MAE选择图像mask的部分的时候,他是随机选的,但是图像的每一部分他所包含的信息是不一样的。所以他的想法就是我想要选信息最多的部分来mask,这样我的模型就更可能学到更多的东西。
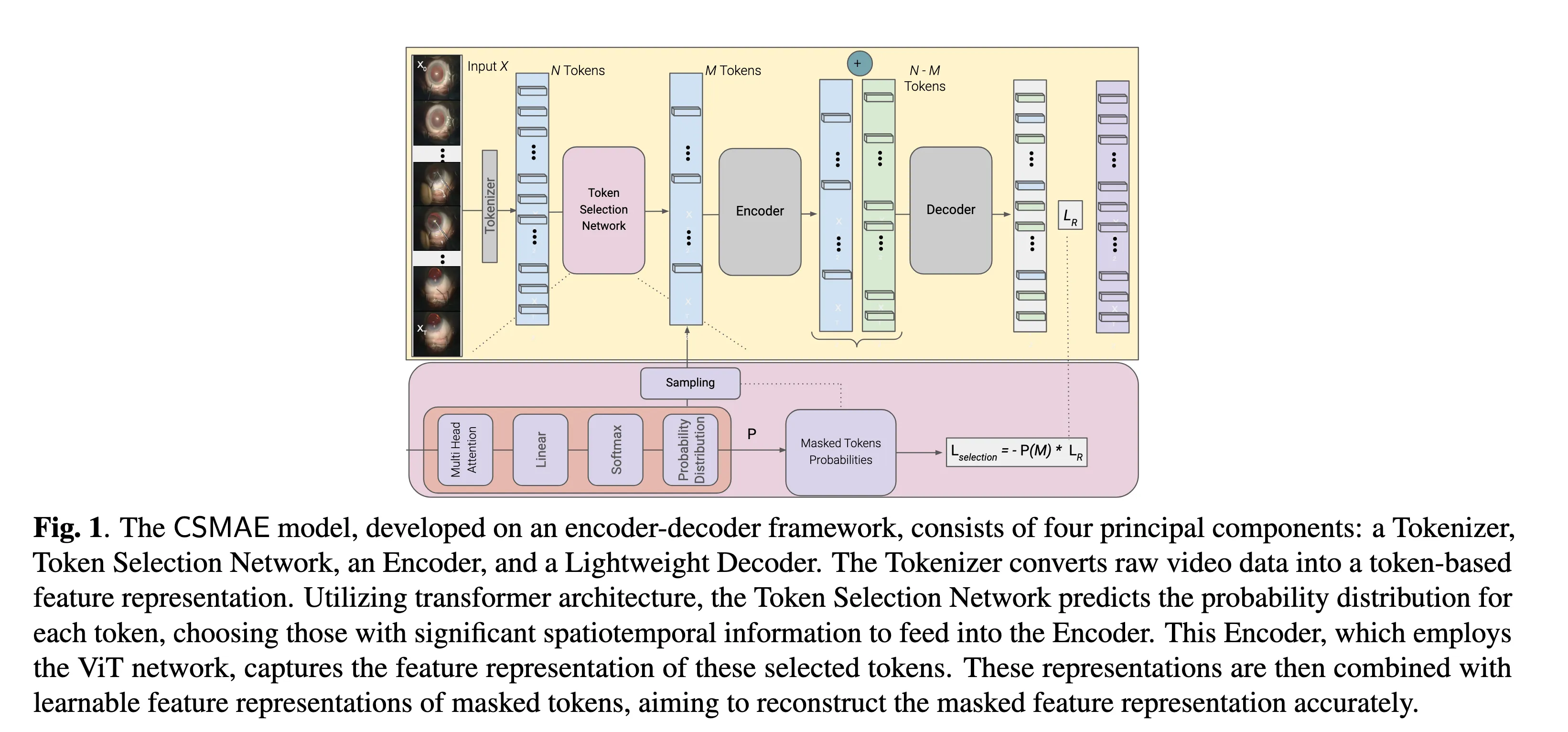
然后他的模型就分为4个部分
Tokenizer#
这里他用3D的CNN来处理视频(T*C*H*W),将视频转化为N个tokens
Token Selection Network#
这里用一个多头注意力层(MHA)+linear layer+Softmax 来计算每个token选择的概率,然后根据一个 掩码率,来决定选多少以及选哪个token来mask。
最终得到M个visible的。
Encoder & Decoder#
这里用的就是两个ViT来encode输入的token然后decode出缺失的图片的部分。
Training#
这里的loss function用的和MAE一样,比较生成 的和ground truth 的差别,然后作为损失函数。
有意思的是文章还使用了一个loss function来专门训练token selection network,他们的想法来自于强化学习中的Gradient-Following algorithm。
他将MAE的架构作为环境,然后 作为奖励,目标就是最大化 。为什么是最大化,我们不应该让损失越来越小吗。答案就是token selection network的作用是为了找到最有价值的patch部分然后把他mask掉,如果我们选择一个信息很小的,模型很容易就预测出来的部分来mask,那就没有很大的作用。而当我们越选择有意义的部分,模型越难预测出来,他的也就会更大,训练速度也会加快,所以对于token selection network而言,他的目的就是目标就是最大化 。
这里取了一个负数,就转换成了我们常规优化中要最小化的目标函数。这里的
- : 第 i 个位置被选中(mask 掉)的概率(由参数控制的策略网络输出)
- : 第 i 个 token 的重建误差(由 MAE 模型参数产生)
但是又有一个问题,模型的两个部分朝着两个方向进行优化,一个想要减小loss,一个想要增加loss,那么就会导致模型的训练一直摇摆,振荡。所以为了解决这个问题,方法就是梯度隔离,token selection network的梯度不回传给MAE,MAE只给个loss给token selection network,也不传给他梯度。他还使用了log缩放,避免概率太小导致的梯度太小。最后的结果应该是这样