CS285 Lecture12 Model-Based Reinforcement Learning
CS285 Lecture12 Model-Based Reinforcement Learning
views
| comments
当我们用model来拟合状态转移函数的时候,我们可以直接通过这个模型进行反向传播
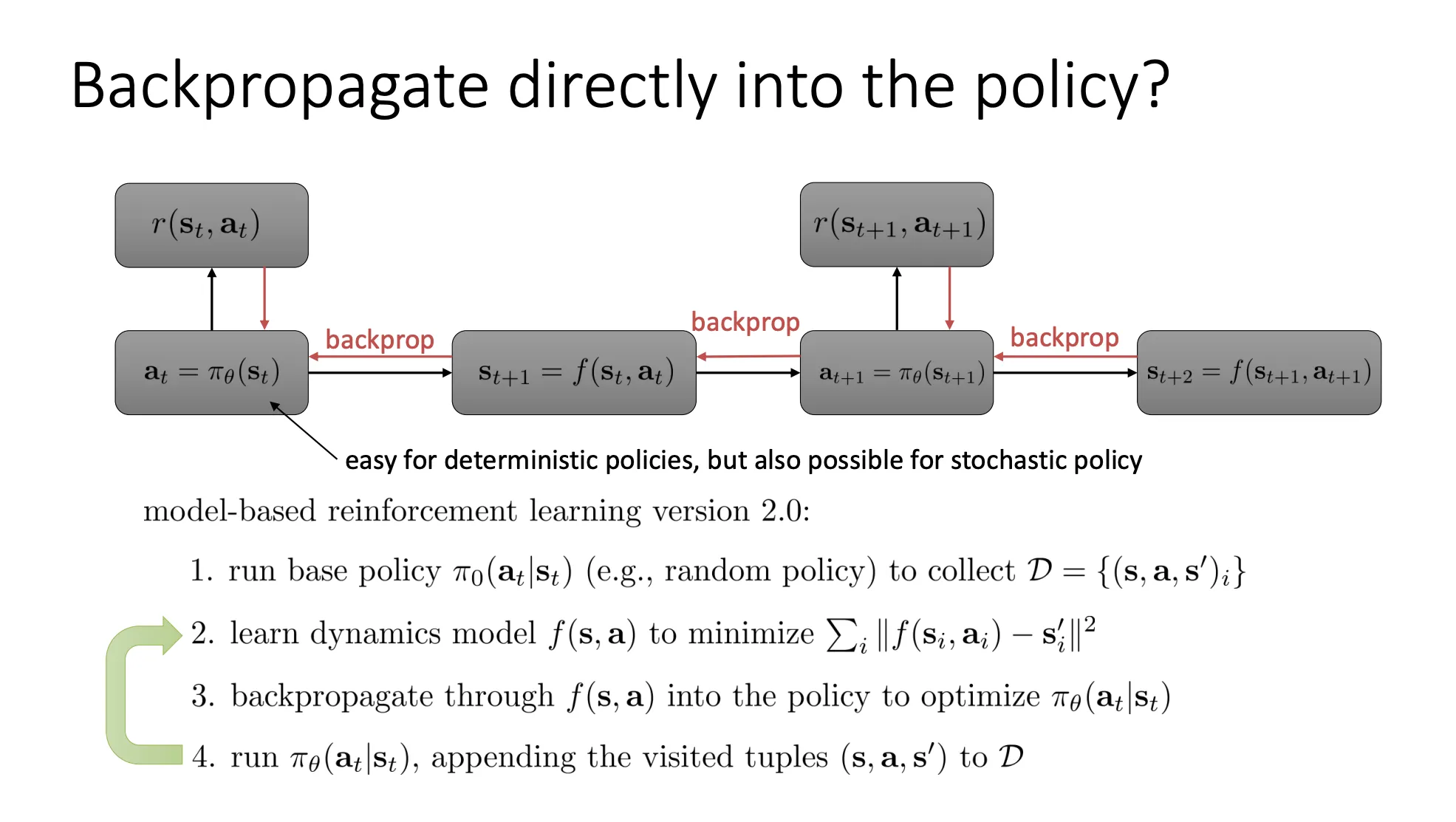 但是这个就有问题
但是这个就有问题
-
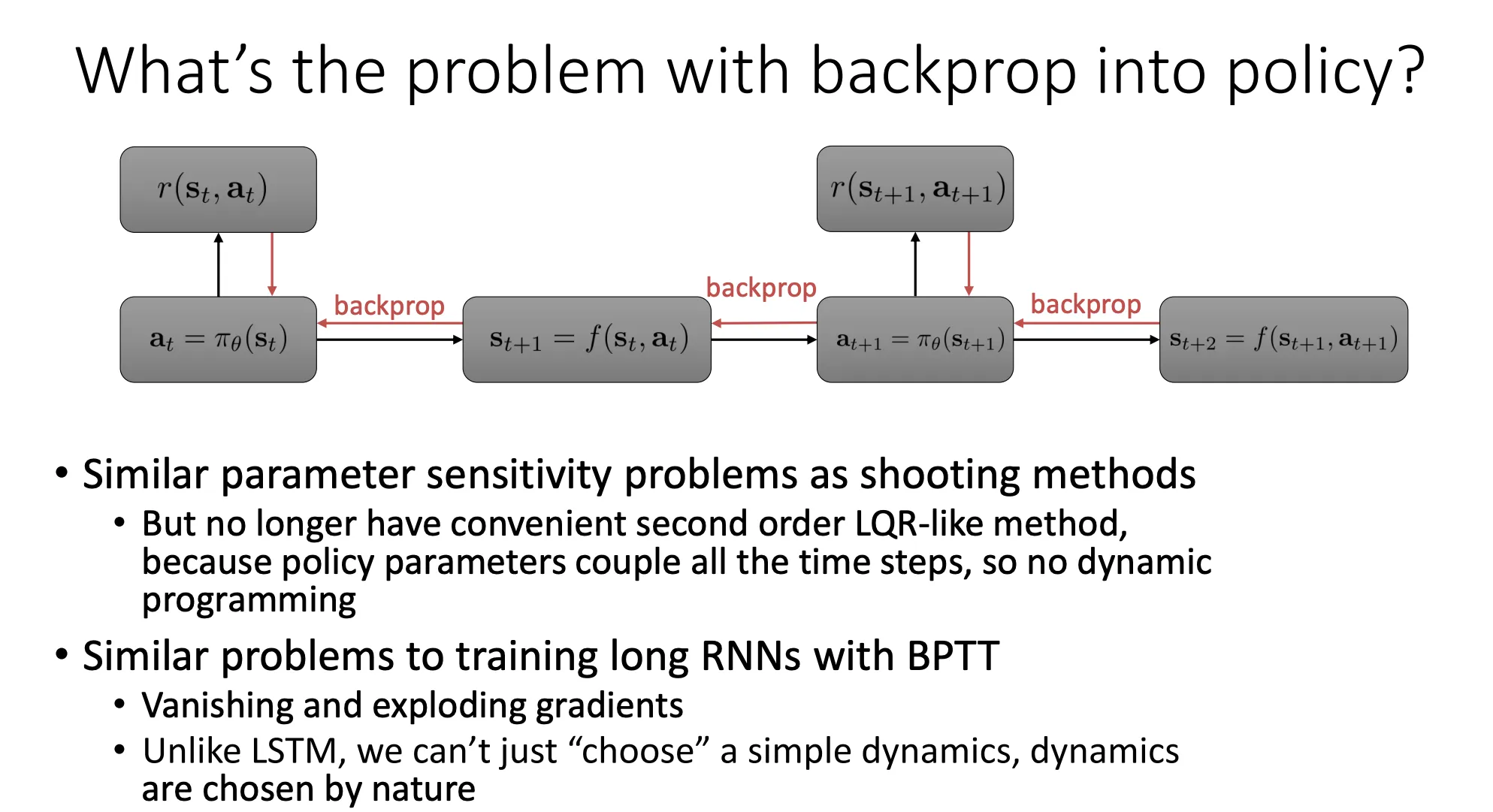
Shooting Method(打靶法): 在轨迹优化中,如果你只调整初始的控制量,试图让几百步之后的机器人达到某个状态,这就像打靶一样——初始角度极其微小的偏差,会被时间无限放大,导致最后偏离十万八千里。
-
耦合问题(Coupling):
- 在传统的控制理论(如 LQR,线性二次调节器)中,我们可以利用动态规划(Dynamic Programming)倒着一步步解出最优控制,每一步是独立的。
- 但在这种深度强化学习方法中,策略网络的参数 是全局共享的(同一个神经网络 用在 所有时间步)。
- 这意味着:你为了优化 时刻的表现去修改 ,会同时改变 时刻的行为。所有时间步被“耦合”在一起了,无法使用类似 LQR 那样高效稳定的解法。这导致优化极其困难,甚至呈病态(Ill-conditioned)。
-
梯度消失与爆炸(Vanishing/Exploding Gradients):
- 这和你训练 RNN 时遇到的问题一模一样。当你在时间轴上展开,反向传播经过 很多次。
- 如果轨迹很长(比如几百步),梯度需要连乘几百个雅可比矩阵(Jacobian Matrix)。这会导致梯度要么变成 0(没信号了),要么变得无限大(数值溢出,网络崩溃)。
-
无法像 LSTM 那样“设计”动力学:
- 这是最痛的一点。在深度学习中,我们发明了 LSTM、GRU 或 ResNet,通过添加“门控”或“残差连接”来人为地让梯度流更顺畅。我们设计了网络结构。
- 但在 RL 中,状态的转移(Dynamics)是由**环境(物理世界)**决定的(即 PPT 说的 “dynamics are chosen by nature”)。
- 如果物理世界本身是混沌的、不连续的(比如机器人脚底打滑、发生碰撞),那么动力学模型 的梯度就会非常难看。我们无法为了好训练而去修改物理定律。
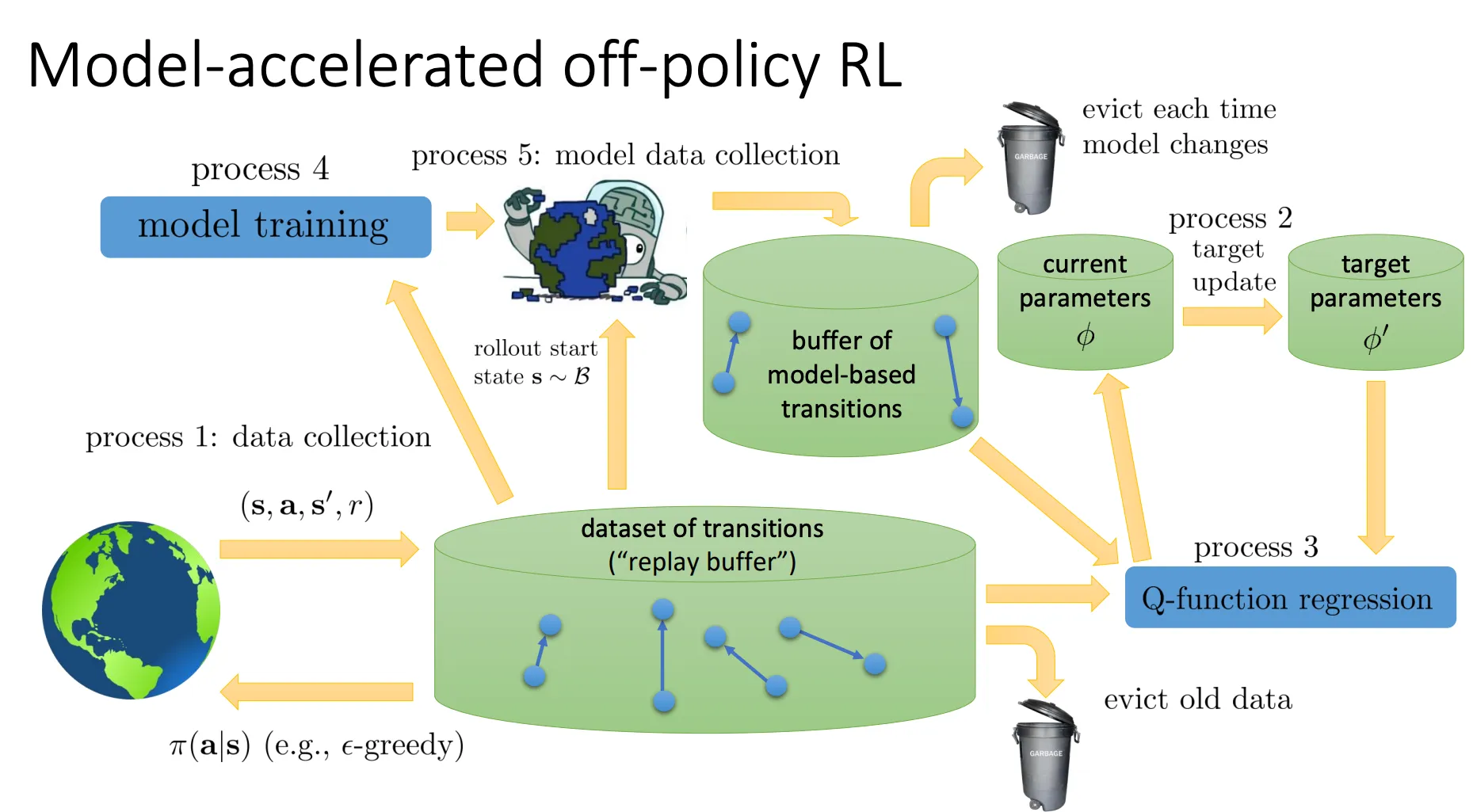
所以我们的方法就是,只用这个model来生成数据来加速model-free的RL算法

Model-Free Learning With a Model#
我们把模型只当作“模拟器”用,而不是“计算图”的一部分。
- 流程:
- 收集真实数据。
- 训练动力学模型 。
- Step 3: 不求导,而是用模型 生成很多虚拟的轨迹(Trajectories)。
- Step 4: 把这些生成的虚拟数据当作“真数据”,喂给一个标准的 Model-Free 算法(如 Policy Gradient )去更新策略。
 但是这就有问题,模型误差积累(Compounding Error)。跟模仿学习中的一样,如果你用有误差的模型预测未来 1000 步,第 1000 步的预测结果可能和真实世界完全无关。
但是这就有问题,模型误差积累(Compounding Error)。跟模仿学习中的一样,如果你用有误差的模型预测未来 1000 步,第 1000 步的预测结果可能和真实世界完全无关。
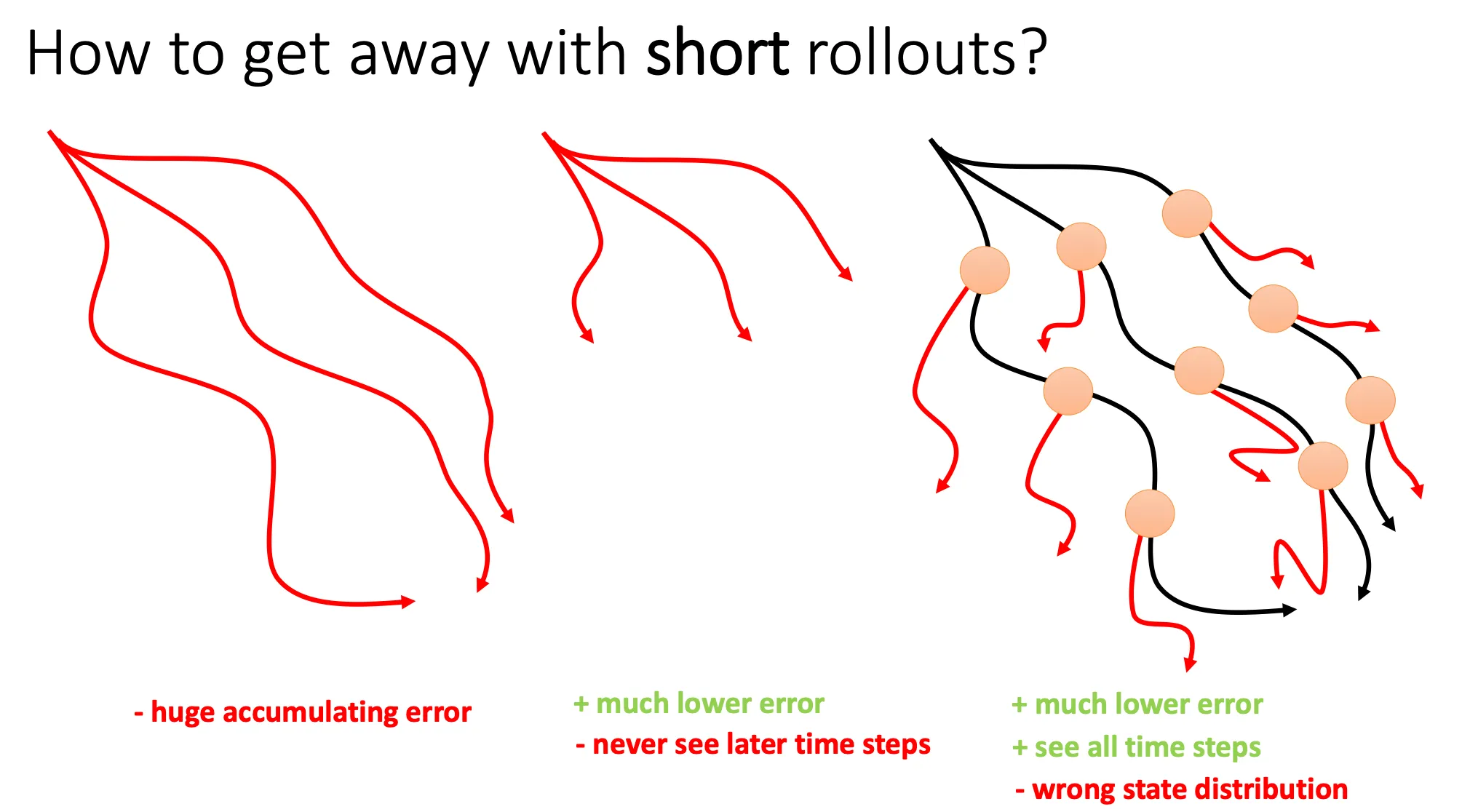
- 左图(Long Rollouts):从初始状态开始,完全由模型长时间推演。缺点:误差积累导致红线(预测)和真实情况偏离十万八千里,策略学了一堆假东西。
- 中图(Short Rollouts from start): 只推演几步。缺点: 误差小了,但智能体看不到未来的长远后果,变得短视。
- 右图(Branched Rollouts / Short Rollouts from Replay Buffer):
- 做法: 从真实数据集中采样真实状态(橙色圆点)作为起点。
- 分支(Branching): 从这些真实的“中间状态”开始,用模型只往后推演很短的几步(比如 k=1 或 k=5)。
- 原理: 既保证了模型误差不会无限放大(因为步数短),又保证了策略能覆盖到整个状态空间(因为起点是从整个历史轨迹中采样的)。
所以最终他的算法流程大概就是这样
 这里特意提到了使用 Off-policy RL。因为生成的短数据并不构成完整的轨迹,且数据分布发生了变化,Off-policy 算法能更高效地利用这些零散的短数据片段。
这里特意提到了使用 Off-policy RL。因为生成的短数据并不构成完整的轨迹,且数据分布发生了变化,Off-policy 算法能更高效地利用这些零散的短数据片段。
Dyna-Style Algorithms#
基本上思想就是类似的