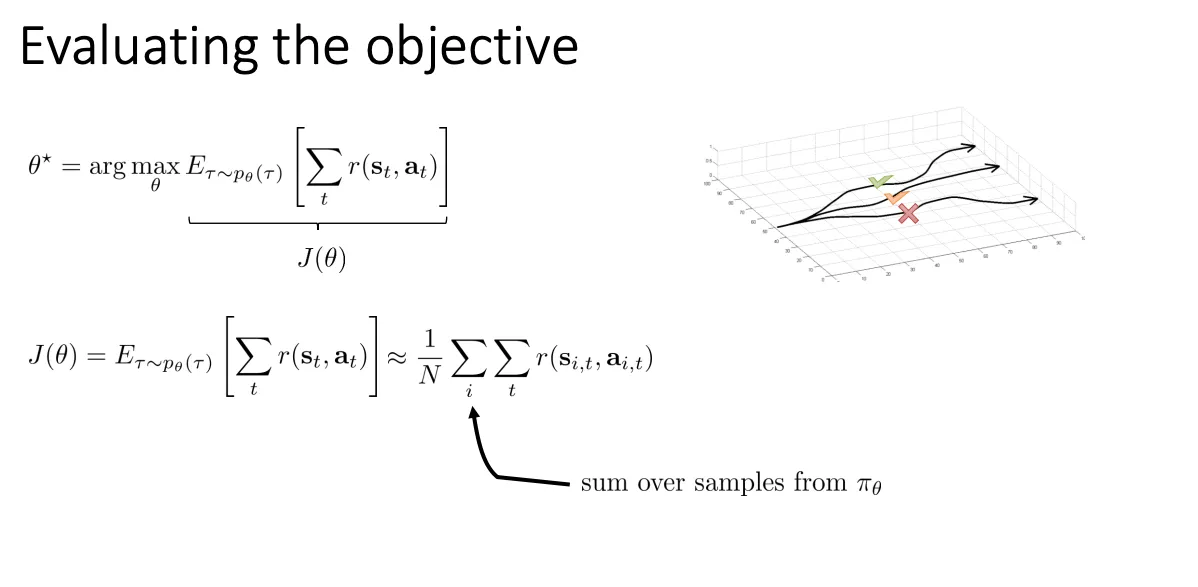
Ploicy algorithm#
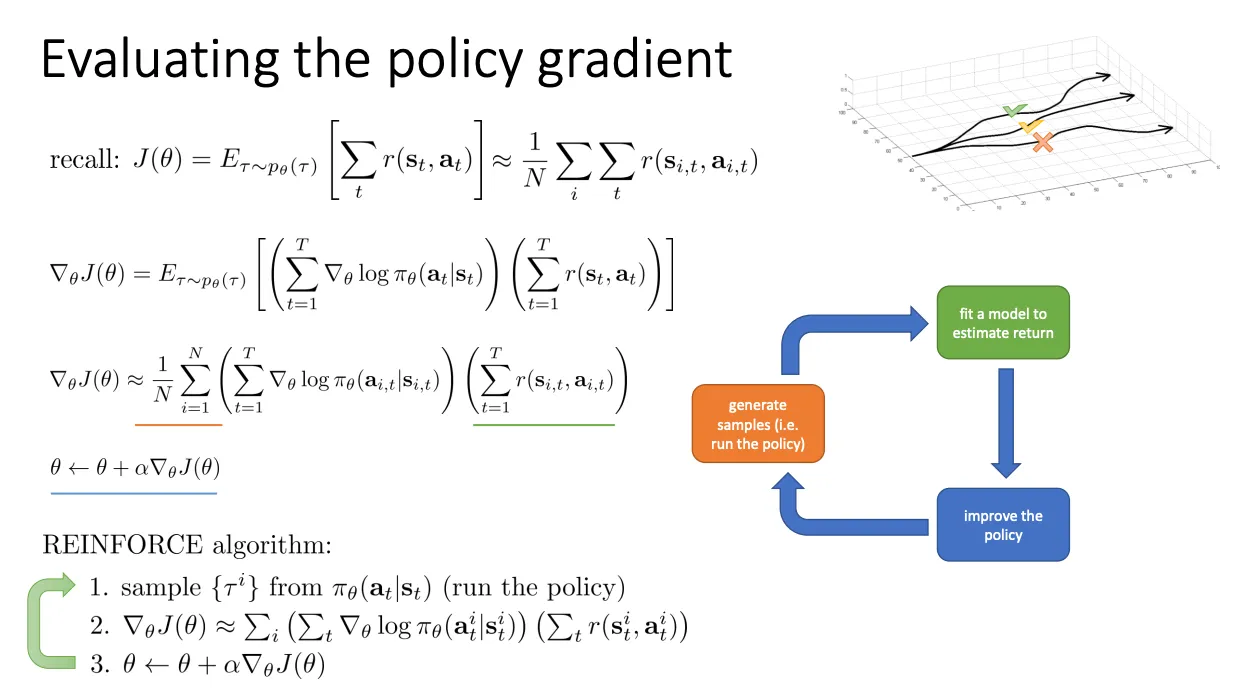
REINFORCE#
初衷是我们并不知道初始状态p(s1) 是多少,也不知道环境转移概率p(st+1∣st,at) ,然后直接对期望求导的话就不能求。于是乎就有一系列数学变化来去掉这两个不知道的部分


但是policy gradient有一个缺陷就是他的方差很大
∇θJ≈∑(梯度方向)×(回报 R)
这里的 R 是一个随机变量。
- 理想情况(低方差): R 总是稳定在 10 左右。那么梯度的长度就很稳定,更新很平滑。
- PG 的情况(高方差): R 可能这次是 100,下次是 -50,再下次是 500。
- 这意味着你的梯度向量 ∇θJ 忽长忽短,甚至方向完全相反。
- 神经网络的参数 θ 就会在参数空间里剧烈震荡,像个没头苍蝇一样乱撞,很难收敛到最优解。
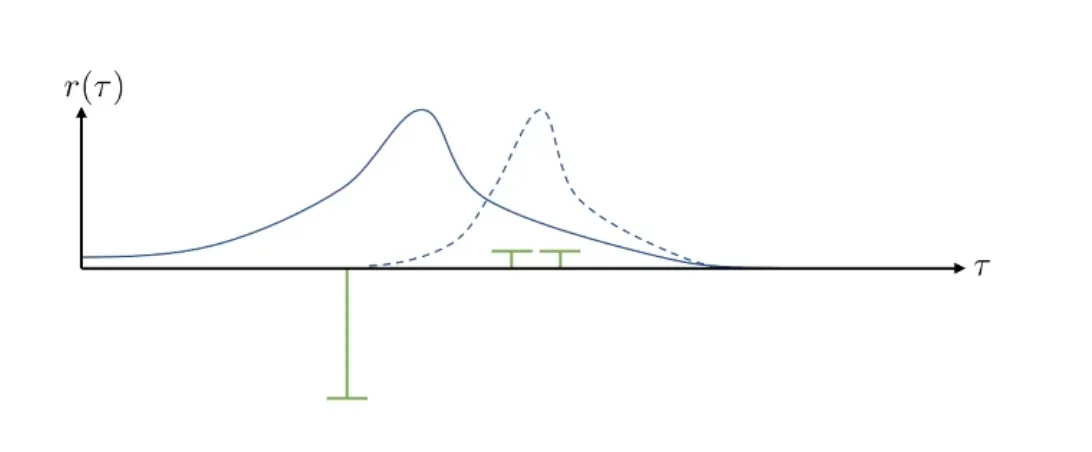
举个例子,假如说图中绿色表示奖励,蓝色表示概率分布,那么看到当前场景,模型会尽力将概率分布从实线的变成虚线的,尽可能减小奖励为负的那部分。
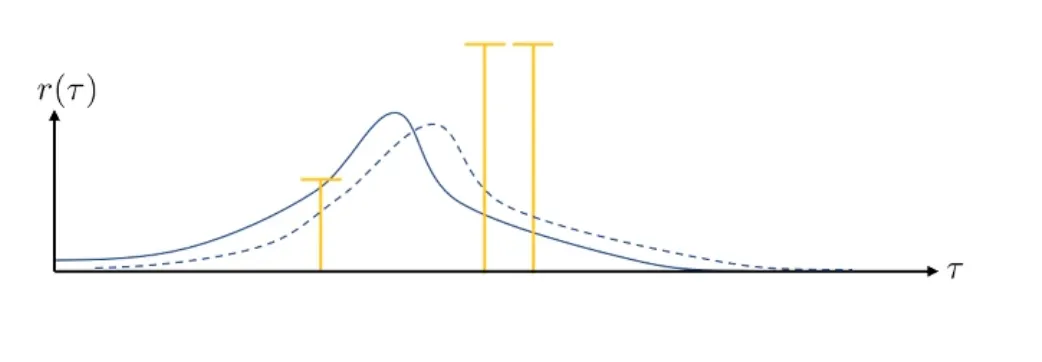
 但是假如我们的奖励之间的相对差没有变,但是所有的奖励都变成正数,那么模型的概率分布就又会变。
但是假如我们的奖励之间的相对差没有变,但是所有的奖励都变成正数,那么模型的概率分布就又会变。
 也就是我们的R 的波动太大,导致他的方差变大不好训练,所以可能需要大量的训练数据来根据大数定律来平均掉波动。当然还有别的方式下面会介绍。
也就是我们的R 的波动太大,导致他的方差变大不好训练,所以可能需要大量的训练数据来根据大数定律来平均掉波动。当然还有别的方式下面会介绍。
Reducing Variance#
显然的是当前的动作只会影响未来的奖励,不会影响之前的奖励,所以我们可以把红色圈中改成计算当前以及以后的奖励而不是从t=1开始计算。
 这样子的好处就是减少了求和总数,必然减少方差的大小。同时他还是无偏的
这样子的好处就是减少了求和总数,必然减少方差的大小。同时他还是无偏的
证明无偏的核心思路是:
我们需要证明被减掉的那部分(即“过去的奖励”与“当前动作梯度”的乘积)在数学期望上等于 0。
如果我们证明了 E[被丢弃的项]=0,那么:
E[新公式]=E[原公式−被丢弃的项]=E[原公式]−0=E[原公式]
既然原公式是无偏的(这是 Policy Gradient 的定义),那么新公式也就是无偏的。
下面是详细的数学推导步骤。
Score Function 的期望为 0。
对于任何概率分布 πθ(x),都有:
Ex∼πθ[∇θlogπθ(x)]=0
证明:
利用对数导数技巧 ∇logf(x)=f(x)∇f(x):
Ex∼πθ[∇θlogπθ(x)]=∫πθ(x)∇θlogπθ(x)dx=∫πθ(x)πθ(x)∇θπθ(x)dx=∫∇θπθ(x)dx=∇θ(∫πθ(x)dx)=∇θ(1)=0
(注:对于离散动作,积分 ∫ 换成求和 ∑ 也是一样的)
结论: 只要这时候乘在这个梯度后面的是一个常数(或者不依赖于当前 x 的项),整个期望就是 0。
原公式里的总回报 ∑t′=1Trt′ 可以拆成两部分:过去的回报(Past)和未来的回报(Future/Reward-to-go)。
针对某一个特定的时刻 t,原公式的期望项是:
E∇θlogπθ(at∣st)⋅过去 (Past)t′=1∑t−1rt′+未来 (Future)t′=t∑Trt′
利用期望的线性性质,我们可以把它拆开:
=新公式 (PPT下半部分)E[∇θlogπθ(at∣st)⋅t′=t∑Trt′]+我们需要证明这项为 0E[∇θlogπθ(at∣st)⋅t′=1∑t−1rt′]
我们要证明的是:
E[∇θlogπθ(at∣st)⋅rpast]=0
这里利用条件期望(Conditional Expectation)。
想象我们在时刻 t,此时状态 st 已经确定,之前的历史(包括过去的奖励 rpast)也都已经发生了,变成了既定事实(常数)。
我们针对当前的动作 at 求期望:
Etrajectory[∇θlogπθ(at∣st)⋅rpast]=Ehistory[Eat∼πθ(⋅∣st)[∇θlogπθ(at∣st)⋅rpast∣st,history]]
因果律 (Causality)
- rpast 是在时刻 t 之前发生的,它不依赖于现在才要做的动作 at。
- 所以在对 at 求期望时,rpast 可以像常数一样被提取出来。
=Ehistoryrpast⋅这正是我们在第1步证明的恒等式,等于 0Eat∼πθ(⋅∣st)[∇θlogπθ(at∣st)]
=Ehistory[rpast⋅0]=0
所以,把“过去的奖励”从公式里删掉,不会改变梯度的期望值(保持无偏),但因为少加了一堆随机数(rpast 在不同轨迹中波动很大),所以显著降低了方差。
还有方法就是给奖励设置baseline,控制奖励在一定范围内波动,最常见的应该是baseline设置为奖励的平均值。同时我们也可以计算这个变化也是无偏的。
 当然我们可以设置更好的baseline值,这就要对方差进行求导。
当然我们可以设置更好的baseline值,这就要对方差进行求导。
 不过在实际操作中,很少用这个。虽然这个公式是理论最优,但在深度强化学习中计算这个加权平均太麻烦了。
不过在实际操作中,很少用这个。虽然这个公式是理论最优,但在深度强化学习中计算这个加权平均太麻烦了。
Off-Policy Policy Gradients#
PG一开始是on policy的,为什么呢,从这两个公式就可以看到
∇θJ(θ)=∫这是概率分布pθ(τ)[∇θlogpθ(τ)r(τ)]dτ
∇θJ(θ)=Eτ∼pθ(τ)[∇θlogpθ(τ)r(τ)]
样本 τ 必须是从 pθ(τ) 这个分布里采样出来的
τ∼pθ(τ)
那么就意味着每次我更新一点参数,我就要重新采集一批数据,这个是非常低效的。于是就有Off-Policy Policy Gradients。
importance sampling#
 我们可以根据绿色方框中的公式变化应用到原本的训练目标中,使得
我们可以根据绿色方框中的公式变化应用到原本的训练目标中,使得
J(θ)=Eτ∼pˉ(τ)[pˉ(τ)pθ(τ)r(τ)]
- r(τ):以前的回报。
- pˉ(τ)pθ(τ):修正系数。
- 如果某条轨迹在当前策略 pθ 下发生的概率很高,但在旧策略 pˉ 下很低,这个系数就会很大(说明这条数据对现在很重要,要重视)。
- 反之系数就会很小。
计算那个修正系数 pˉ(τ)pθ(τ) 看起来很难,因为轨迹 τ 包含了一堆东西:
p(τ)=p(s1)∏π(a∣s)p(s′∣s,a)
这里面包含了 环境的物理规律(Dynamics) p(s′∣s,a),这通常是我们不知道的(比如风速怎么变、摩擦力是多少)。
但是当我们做除法时:
pˉ(τ)pθ(τ)=p(s1)∏πˉ(a∣s)p(s′∣s,a)p(s1)∏πθ(a∣s)p(s′∣s,a)
- 初始状态概率 p(s1):上下都有,消掉(红线划掉的部分)。
- 环境转移概率 p(s′∣s,a):客观世界规律不随你的策略改变,上下都有,消掉(红线划掉的部分)。
最终结果:
pˉ(τ)pθ(τ)=∏πˉ(at∣st)∏πθ(at∣st)
之后我们将上述技巧用在PG中
 我们看最上面的公式:
我们看最上面的公式:
∇θ′J(θ′)=Eτ∼pθ(τ)[pθ(τ)pθ′(τ)∇θ′logπθ′(τ)r(τ)]
这里有三个核心组件,我们需要把它们都按时间步 t 展开:
- 重要性权重(Importance Weight) pθ(τ)pθ′(τ):
- 轨迹概率 p(τ)=p(s1)∏π(a∣s)p(s′∣s,a)。
- 环境动力学 p(s′∣s,a) 和初始分布 p(s1) 在分子分母中是一样的,直接消掉。
- 只剩下策略的连乘:
pθ(τ)pθ′(τ)=t=1∏Tπθ(at∣st)πθ′(at∣st)
- 梯度项 ∇θ′logπθ′(τ):
- 因为 log(∏x)=∑logx。
- 所以整条轨迹的 log 概率梯度,等于每个时间步动作概率梯度的和:
t=1∑T∇θ′logπθ′(at∣st)
- 总回报 r(τ):
- 就是所有时间步奖励的和:∑t=1Tr(st,at)。
当我们把上面三个展开式代回去,就得到了 PPT 中间那个长公式:
=E[(t=1∏Tπθπθ′)(t=1∑T∇logπθ′)(t=1∑Tr)]
为了分析第 t 个时刻的梯度 ∇θ′logπθ′(at∣st) 到底该乘以什么权重,我们把连乘部分拆成了两半:过去和未来。
公式变成了:
=Et=1∑T∇θ′logπθ′(at∣st)过去t′=1∏tπθπθ′(∑r)未来t′′=t∏Tπθπθ′
必须要保留的(左边的连乘):
PPT 用箭头指出:“future actions don’t affect current weight”。
- 含义:我们在时刻 t 做决定时,能不能到达这个状态 st,完全取决于过去(1 到 t)发生了什么。
- 解释:如果新策略 πθ′ 和旧策略 πθ 在过去差别很大,那么 st 的出现概率就不一样,这个权重(Ratio)必须保留,用来修正状态分布的偏差。
右边的部分忽视掉,后面的章节会讲解为什么可以。
然后我们进一步处理转化后公式中连乘的那一项
 连乘的那个比值哪怕每一项都只偏离一点点(比如 1.1 或 0.9),如果你乘上 100 步(1.1100),这个数值就会变得巨大或者接近于零。这会让梯度计算极其不稳定(方差极大)。
连乘的那个比值哪怕每一项都只偏离一点点(比如 1.1 或 0.9),如果你乘上 100 步(1.1100),这个数值就会变得巨大或者接近于零。这会让梯度计算极其不稳定(方差极大)。
我们可以根据下面这个公式
k=1∏t−1πθ(ak∣sk)πθ′(ak∣sk)≈pθ(st)pθ′(st)
转化一下
Wt=Part A: 走到当前状态的概率比(k=1∏t−1πθ(ak∣sk)πθ′(ak∣sk))⋅Part B: 当前动作的概率比(πθ(at∣st)πθ′(at∣st))
这一长串过去的动作概率比值 ∏k=1t−1…,决定了你有多大可能到达现在的状态 st
然后
Wt≈pθ(st)pθ′(st)⋅πθ(at∣st)πθ′(at∣st)
πθ(s)πθ′(s)=pθ(st)pθ′(st)
然后我们假设“前面的 t−1 步里,新策略和旧策略的表现完全一样,没有产生任何累积的偏差。”,这也就是ppt中划掉的那一部分。于是乎,我们将连乘那部分解决了。
Advanced Policy Gradients#

我们在使用标准梯度下降的时候公式是
θ←θ+α∇θJ(θ)
但这个往往表现不好,原因就是参数空间(θ)和概率分布空间(πθ)是不一样的。有的参数动一点点(比如方差 σ 很小时的均值 k),概率分布会剧烈变化。有的参数动很大(比如方差 σ 很大时的均值 k),概率分布几乎不变。如果我们不管三七二十一,对所有参数都用同样的步长 α 去更新,就会导致上梯度的“震荡”或“停滞”。
从数学上定义这个优化过程就是
θ′←argθ′max(θ′−θ)T∇θJ(θ)s.t.∥θ′−θ∥2≤ϵ
怎么理解这个公式呢
目标函数:maxθ′(θ′−θ)T∇θJ(θ)
这一项其实是对 J(θ′) 的一阶泰勒展开(线性近似)。
- 推导逻辑:
根据泰勒展开,新位置的函数值 J(θ′) 约等于:
J(θ′)≈J(θ)+(θ′−θ)T∇θJ(θ)
- 含义:
- 因为 J(θ) 是常数(起点的分数值),所以我们要最大化 J(θ′),就等同于最大化后面那一坨:(θ′−θ)T∇θJ(θ)。
- 向量视角:这也是两个向量的点积。要让点积最大,更新方向 (θ′−θ) 必须和 梯度方向 ∇θJ(θ) 平行且同向。
- 就是“我要沿着坡度最陡的方向往上爬。”
约束条件:s.t.∥θ′−θ∥2≤ϵ
这一项限制了更新的步长。
- 含义:
- ∥⋅∥2 是欧几里得距离的平方。
- ϵ 是一个很小的常数(可以理解为圆的半径)。
- “但是,我不允许你一步走太远。你只能在以当前位置为中心、半径为 ϵ 的圆圈(或者球体)里面找新的落脚点。”
如果你用拉格朗日乘子法去解上面这个带约束的优化问题:
L=(θ′−θ)T∇J−λ(∥θ′−θ∥2−ϵ)
对 θ′ 求导并令其为 0,你会得到结果:
θ′−θ=2λ1∇θJ(θ)
令 α=2λ1(学习率),这就变成了我们最熟悉的公式:
θ′=θ+α∇θJ(θ)
那么本质就是在欧几里得空间的一个小圆球内,寻找让目标函数线性增长最快的方向。
但是问题就是我们尝试优化的这个参数空间并不是我们的策略空间
1. 参数空间 (Parameter Space, Θ)#
- 定义:这是你的神经网络(或任何模型)内部权重的集合。
- 具体样子:如果你有一个神经网络,它的所有权重和偏置组成了一个长向量 θ=[θ1,θ2,…,θn]。这个向量所在的 n 维空间就是参数空间。
- 度量方式:通常用欧几里得距离(Euclidean Distance)。
- 比如 θ 和 θ′ 的距离是 ∥θ−θ′∥2。
- 这就好比你在直角坐标系里量两个点的直线距离。
- 你可以控制这里:梯度下降算法(SGD, Adam)直接修改的就是这堆数字。
2. 策略分布空间 (Policy Distribution Space, Π)#
- 定义:这是你的智能体(Agent)在面对环境时,输出的概率分布的集合。
- 具体样子:对于每一个状态 s,智能体都会输出一个动作的概率分布 πθ(a∣s)。所有可能的概率分布构成了这个空间。
- 度量方式:通常用 KL 散度(KL Divergence)。
- 它衡量的是“两个概率分布有多不一样”。
- 这实际上是一个弯曲的黎曼流形(Riemannian Manifold),而不是平坦的欧几里得空间。
- 你真正在乎的是这里:你并不关心 θ 是 0.1 还是 0.2,你只关心“智能体向左走的概率”是 10% 还是 90%。
3. 核心矛盾:两个空间的“映射”是扭曲的#
在标准的梯度下降(Vanilla PG)中,我们假设:参数变动一点点 ≈ 策略行为变动一点点。
但在强化学习里,这个假设经常完全崩溃。
- 标准梯度下降(Vanilla PG):
它是在参数空间里走路。它说:“我要把参数 θ 挪动 0.01 的距离”。
- 风险:它不知道这 0.01 在另一边(策略空间)意味着是“迈了一小步”还是“跳下了悬崖”。
- 自然梯度 / TRPO / PPO:
它们是在策略分布空间里走路。它说:“我要让策略的概率分布改变 0.01(KL 散度)”。
- 做法:它会反推回参数空间——“为了让概率只变 0.01,我的参数 θ 到底应该动多少?”
- 如果在敏感区,参数就只动 0.00001。
- 如果在平原区,参数就大胆动 10.0。
- 好处:稳定且高效。
于是我们可以改变约束条件,我们的优化目标还是不变
θ′←argθ′max(θ′−θ)T∇θJ(θ)s.t.D(πθ′,πθ)≤ϵ
新的约束:D(πθ′,πθ)≤ϵ。计算的是两个概率分布的KL散度,描述两个概率分布的差距。我们约束前后两个概率分布的差距在一定范围内然后找最优解。
虽然 KL 散度很好,但它计算起来很复杂。为了在计算机里快速求解,我们需要对它进行近似。
PPT 下半部分展示了如何把 KL 散度转化为二次型(Quadratic Form):
-
KL 散度的泰勒展开:
如果在 θ 附近对 DKL(πθ′∣∣πθ) 进行二阶泰勒展开,你会发现:
- 零阶项(常数)是 0(因为自己和自己的距离是 0)。
- 一阶项(梯度)是 0(因为 KL 散度在 θ′=θ 处取极小值)。
- 二阶项(海森矩阵 Hessian)才是关键。
-
引入 Fisher 信息矩阵(Matrix F):
PPT 给出了近似公式:
DKL(πθ′∣∣πθ)≈(θ′−θ)TF(θ′−θ)
这里的 F 就是 Fisher Information Matrix (FIM)。
它的定义在右下角:
F=Eπθ[∇θlogπθ(a∣s)∇θlogπθ(a∣s)T]
可以把 F 理解为一个“地形校正器”或“曲率矩阵”。
- 它是 KL 散度的二阶导数:它告诉我们在当前的参数位置,策略分布对于参数变化有多敏感。
- 如果某个方向上 F 的值很大(曲率大),说明参数稍微动一下,KL 散度就剧增(策略变化很大)。
- 如果某个方向上 F 的值很小(曲率小),说明参数动很多,KL 散度才变一点点。
自然梯度更新(Natural Gradient Update)
如果我们把这个新的约束((θ′−θ)TF(θ′−θ)≤ϵ)代入优化问题求解,我们会得到自然梯度更新公式:
θnew=θold+αF−1∇θJ(θ)
请注意那个 F−1(Fisher 矩阵的逆):
- 这就是 PPT 问的 “rescale”。
- 它自动抵消了地形的崎岖:
- 在陡峭的地方(F 大),F−1 会把梯度缩小,防止步子迈太大。
- 在平坦的地方(F 小),F−1 会把梯度放大,防止停滞不前。
