目标检测 FPN CVPR 2017 论文笔记
Feature Pyramid Networks for Object Detection
前言#
在目标检测任务中,不同尺度下的目标识别是一个很大的挑战。原来多数的object detection算法都是只采用顶层特征(卷积最后一层)做预测,低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。
那如果想引入不同尺度的特征,应该怎么做呢?
FPN#
主要有这么几种方法
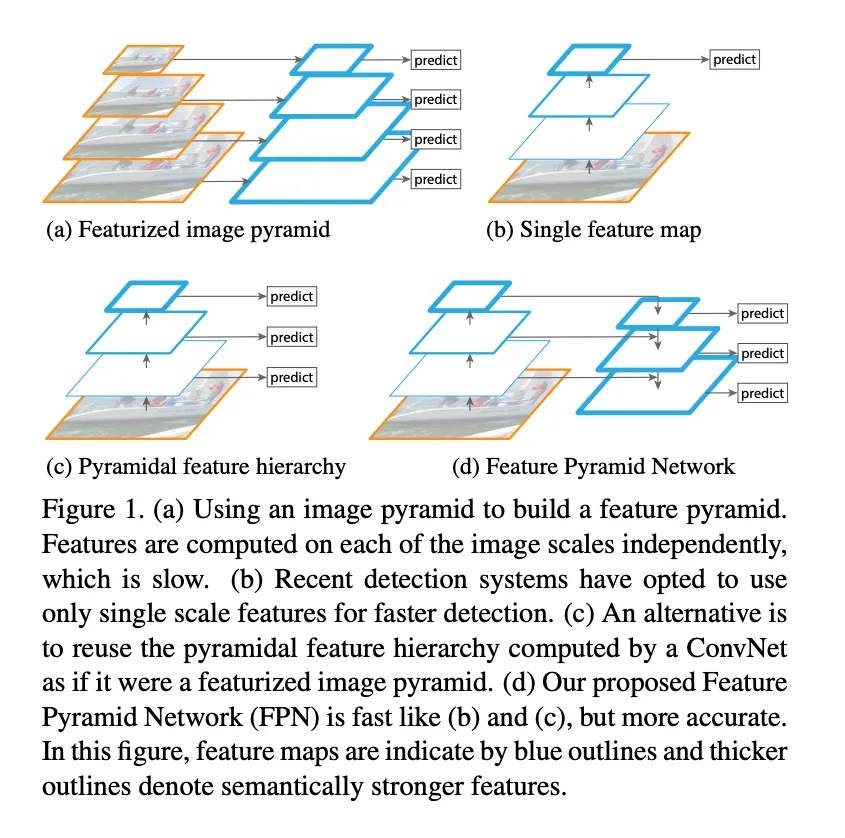 (a) Featurized image pyramid:这种方式就是先把图片弄成不同尺寸的,然后再对每种尺寸的图片提取不同尺度的特征,再对每个尺度的特征都进行单独的预测,这种方式的优点是不同尺度的特征都可以包含很丰富的语义信息,但是缺点就是时间成本太高。
(a) Featurized image pyramid:这种方式就是先把图片弄成不同尺寸的,然后再对每种尺寸的图片提取不同尺度的特征,再对每个尺度的特征都进行单独的预测,这种方式的优点是不同尺度的特征都可以包含很丰富的语义信息,但是缺点就是时间成本太高。
(b) CNN网络最常用的结构,只用最后一层卷积后的feature map
(c) SSD的做法,从conv4开始每一层的feature map都用来做预测,这样就得到了多尺度下的特征,显然这种做法是没有增加任何计算量的,不过FPN的作者说SSD没有用更底层的特征,而更底层的特征对小目标识别有优势。
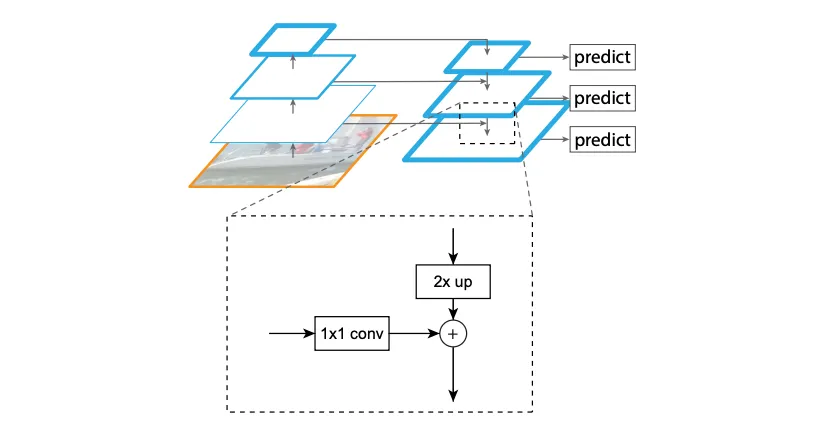
(d) FPN的网络架构。从图中可以看出,就是多了一个上采样的过程,feature map上采样,然后和更浅层的特征融合,再独立做预测。
主要想法就是
左边部分就是传统的卷积操作,每次经过一层卷积图片的分辨率就会减小,然后越底层卷积之后的特征图他包含的细节就更多,越高层的特征图他包含的语义信息就越多,但是细节就没有这么多。左边逐渐往上的部分论文称之为bottom up。
然后,左层的最上面的特征图经过一个1*1的卷积核改变通道数,不改变分辨率,然后就作为右边的最顶层。右边逐渐往下被称之为top down。主要是为了上采样然后融合covnet提取出的顶层和底层的信息,具体而言就是右边每一层的特征图经过*2的放大采样。
采样方法是最近邻上采样,使得特征图扩大2倍。上采样的目的就是放大图片,在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的像素,在本文中使用的是最近邻上采样(插值)
从而使得特征图和左下层的特征图大小保持一致,然后左层的特征图经过1*1的卷积核匹配通道数之后与右层放大后的特征图直接相加,以此类推。
然后对于右边的每一层经过一个3*3的卷积核可以直接输出用于predict,使用这个3*3卷积的目的是为了消除上采样产生的混叠效应(aliasing effect),混叠效应应该就是指上边提到的‘插值生成的图像灰度不连续,在灰度变化的地方可能出现明显的锯齿状。这样就得到了多尺度的特征。